
本地缓存Caffeine
相关参考:结合我司应用,给你分享全网最全的Caffeine教程、性能利器Caffeine缓存全面指南 、本地缓存:为什么要用本地缓存?
概述
Caffeine 是基于Java 8 开发的、提供了近乎最佳命中率的高性能本地缓存组件。它的设计初衷就是替代Guava缓存,提供更加高效的缓存解决方案。为什么要替代Guava呢?因为Guava虽好,但在处理高并发和大数据量时,性能就显得有点吃力。Caffeine 的特点可以用三个词概括:快、简单、强大。
为什么要使用本地缓存
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
两级缓存的访问流程如下图:
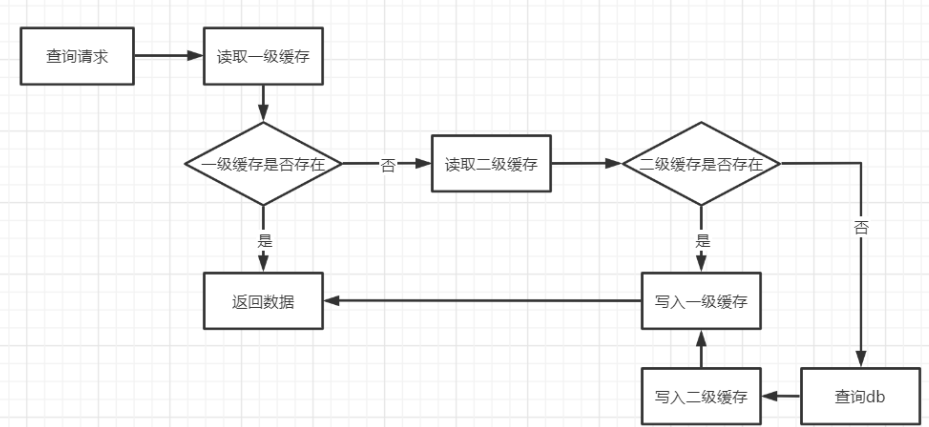
本地缓存的优点:
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
- 使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
特点
Caffeine提供了灵活的构造器去创建一个拥有下列特性的缓存:
- 自动把数据加载到本地缓存中,并且可以配置异步;
- 当达到最大容量的时候,使用基于数量剔除策略;
- 基于失效时间剔除策略,这个时间是从最后一次操作算起【访问或者写入】;
- 异步刷新
- key将自动被弱引用所封装
- value将自动被弱引用或者软引用所封装
- 数据剔除提醒;
- 写入广播机制;
- 缓存访问可以统计
内部结构
Caffeine的内部结构:
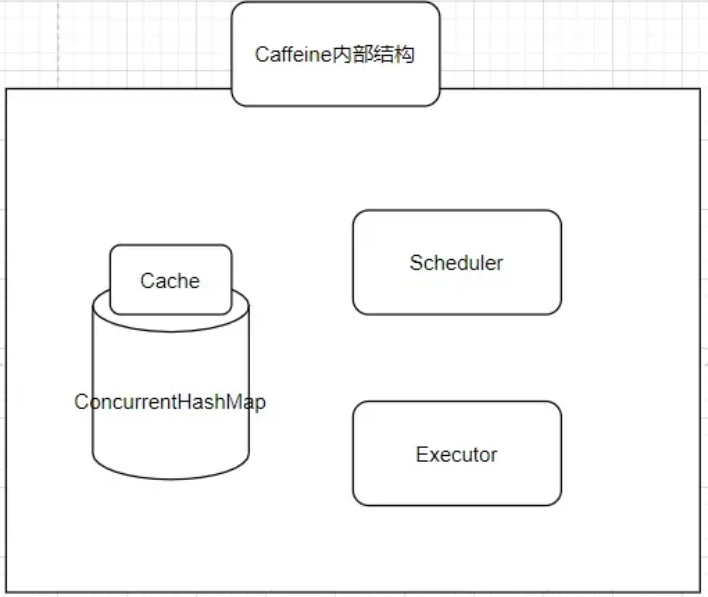
- Cache的内部包含着一个ConcurrentHashMap,这是存放所有缓存数据的地方,ConcurrentHashMap是一个并发安全的容器,可以说Caffeine其实就是一个被强化过的ConcurrentHashMap。
- Scheduler:定期清空数据的一个机制,可以不设置,如果不设置则不会主动的清空过期数据。
- Executor:指定运行异步任务时要使用的线程池。可以不设置,如果不设置则会使用默认的线程池,也就是ForkJoinPool.commonPool()。
核心原理
Caffeine的核心功能和原理,主要体现在它的高性能和智能缓存策略上。
首要的是Caffeine的缓存策略。大部分缓存系统都面临一个问题:怎样决定保留或丢弃缓存中的数据?Caffeine在这方面做得很棒,它采用了一种叫做”Window TinyLFU”(最少最近使用)的策略(一种结合LRU、LFU优点的算法)。这个策略的核心思想是:如果一个数据最近被频繁访问,那么它在不久的将来也很可能被访问。因此,Caffeine会优先保留这些“热门”数据。
但Caffeine的聪明之处不止于此。它还实现了一种自适应的缓存驱逐策略,这意味着它能够根据实际的访问模式来动态调整缓存的行为。比如,如果咱们的应用在某个时间段内频繁访问某类数据,Caffeine会自动调整,确保这些数据更长时间地留在缓存中。
简单示例体会Caffeine的功能:
1 | Cache<String, String> cache = Caffeine.newBuilder() |
上述代码示例中,创建了一个最大容量为10000的Caffeine缓存,设置了10分钟的访问过期时间,并开启了统计功能。这样,就能看到缓存的命中率等重要信息,从而更好地理解和调优缓存的表现。
优缺点
优点:
- 高性能:Caffeine 是为了提供高性能而设计的。它采用了多种优化技术,如使用内存预分配、并发数据结构和高效的数据访问算法,以实现快速的缓存访问和更新操作。
- 内存管理:Caffeine 提供了一些内存管理策略,可根据应用程序的需求自动管理缓存中的数据。它支持基于大小的驱逐策略,可以根据缓存项的大小自动释放内存空间。
- 强大的功能:Caffeine 提供了许多实用的功能,如缓存项的过期控制、异步加载、统计信息收集等。这些功能使得开发人员能够更好地控制缓存的行为,并根据具体需求进行配置。
- 无缝集成:以很容易地与Spring Boot集成,这使得在Spring Boot应用中使用Caffeine成为了一个简单而有效的提升性能的方式。
缺点:
- Java 限定:Caffeine 是一个针对 Java 语言的缓存库,因此它的使用局限于 Java 开发环境。
- 分布式支持有限:Caffeine 是一个本地缓存库,主要用于单个应用程序的内存缓存。如果需要在分布式环境下使用缓存,例如在多个节点之间共享缓存数据,那么Caffeine 的功能可能有限。
使用
基础使用
Maven中导入如下依赖即可:
1 | <dependency> |
基础使用例子:
1 | import com.github.benmanes.caffeine.cache.Cache; |
高级功能
后续完善
SpringBoot集成
后续完善
常见的本地缓存
ConcurrentHashMap实现本地缓存:
- 缓存的本质就是存储在内存中的KV数据结构,对应的就是jdk中线程安全的ConcurrentHashMap,但是要实现缓存,还需要考虑淘汰、最大限制、缓存过期时间淘汰等等功能;优点是实现简单,不需要引入第三方包,比较适合一些简单的业务场景。缺点是如果需要更多的特性,需要定制化开发,成本会比较高,并且稳定性和可靠性也难以保障。对于比较复杂的场景,建议使用比较稳定的开源工具。
Guava Cache:
- Guava /ˈɡwɑːvə/ 是一个功能强大的 Java 工具库,其中包含了 Guava Cache。它提供了简单易用的本地缓存实现,基于LRU缓存策略。具有类似于 Caffeine 的特性,如大小限制、过期控制、并发访问等。Guava Cache 是 Caffeine 的前身,因此它们之间有很多相似之处。
Ehcache:
- Ehcache 是一个流行的开源 Java 缓存库,提供了丰富的功能和配置选项。它支持多种缓存策略,如 LRU、LFU、FIFO 等,并且具有可插拔的缓存存储和高级功能,如分布式缓存、缓存预热、缓存事件监听等。